
# JS相关
# 连续赋值
var a = {
n: 1,
x: 3
}
a.x = a = { n: 2};
console.log(a.x); // ?
2
3
4
5
6
- 理解:正常时从右到左赋值,但是【.】操作符比【=】操作符优先级高,所以先走a.x的赋值
var a = {
n: 1,
x: 3
}
// a.x = a = { n: 2};
a.x = a;
a = {n: 2}; // 引用赋值,所以现在 a = {n: 2},a.x消失
console.log(a.x); // undefined
2
3
4
5
6
7
8
- 证明猜测
let me = {
name: 'hdy',
age: 18,
books: [
'红宝书',
'蝴蝶书'
]
}
me.name = me = me.books;
console.log(me); // ['红宝书', '蝴蝶书']
/**
* 1. me.name = me.books; ['红宝书', '蝴蝶书']
* 2. me = me.books; ['红宝书', '蝴蝶书']
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# Vue3
- Vue3做了哪些性能上的提升?
- defineProperty改proxy,新增属性也有响应式
- 对虚拟DOM提升:将不依赖响应式数据的VNode进行作用域提升,第二次调用render时,直接复用旧的VNode
- diff算法的提升:提升作用域的VNode也不做diff算法,因为不依赖响应式数据的DOM不会因为数据的改变而变化
- blockTree:生成一个
dynamicChildren数组,将引用动态数据的元素收集起来。 - Vue是以组件为粒度更新数据的,所以每个组件有一个dynamicChildren数组,更新时只diff这一部分的VNode
- blockTree:生成一个
- 增加了CompositionAPI,有了类似react hook的写法,能够将数据逻辑抽离
- 能够增强代码的复用性,同一个数据以及数据的处理方法可以进行hooks抽取复用
- 将数据和数据处理的方法进行抽取,在编写代码时有更强的逻辑的连续性,体验会更好。
# JSONP原理
- 前后端约定一个函数名。
- 前端定义函数,并制造一个script标签去请求跨域数据。
- 后端返回函数的调用代码,并将数据以参数的形式传入。
const express = require('express');
const app = new express();
app.listen(8888,() => {
console.log('listen 8888');
});
app.get('/', (req, res) => res.send(`
<body>
<div>首页</div>
<script>
const name = 'hdy'
let user;
function getUser(userData) {
user = userData;
}
setTimeout(() => {
const script = document.createElement('script');
script.src = 'http://localhost:8889?name=' + name
document.body.appendChild(script);
// 请求回来后本地user读取正确
setTimeout(() => console.log(user), 2000);
// {"name":"hdy","age":18,"major":"软件工程"}
}, 2000);
</script>
</body>
`));
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
const express = require('express');
const app = new express();
app.listen(8889, () => {
console.log('listen 8889');
});
const database = {
hdy: {
name: 'hdy',
age: 18,
major: '软件工程'
},
zs: {
name: '张三',
age: 20,
major: '法律'
}
}
app.get('/', function(req, res) {
const name = req.query.name;
const data = database[name] ? JSON.stringify(database[name]) : '{}';
// 入参到前端会直接解析成对象,因为这是script标签返回内容字段
res.send(`getUser(${data})`);
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# async/defer
- 相同点: 异步加载 (fetch)
- 不同点:
- async 加载(fetch)完成后立即执行 (execution),因此可能会阻塞 DOM 解析;
- defer 加载(fetch)完成后延迟到 DOM 解析完成后才会执行(execution),但会在事件 DomContentLoaded 之前
# 操作系统相关
# 线程和进程
- 线程是进程的最小执行单位
- 进程是系统分配资源的最小单位
- 线程使用进程分配的资源执行
- 执行时可以给资源上锁,使用完后解锁,其他资源才可以使用
- JS是单线程语言,但是使用worker可以多开一个线程
- 浏览器是多线程工作的,内部主要线程有:
- JS引擎线程
- GUI渲染线程(渲染页面)
- 事件触发线程
- 定时器触发线程
- http请求线程
- 其他线程
- 如果要在系统内多开一个线程shell命令:shell代码后加【&】
# 无多线程
for ((i=0;i<5;i++))
do
{
sleep 3
echo "${i} done!" >> log.txt
}
done
wait
2
3
4
5
6
7
8
9
# 当前代码多开一个线程后台执行
for ((i=0;i<5;i++))
do
{
sleep 3
echo "${i} done!" >> log.txt
} &
done
wait
2
3
4
5
6
7
8
9
# 网络相关
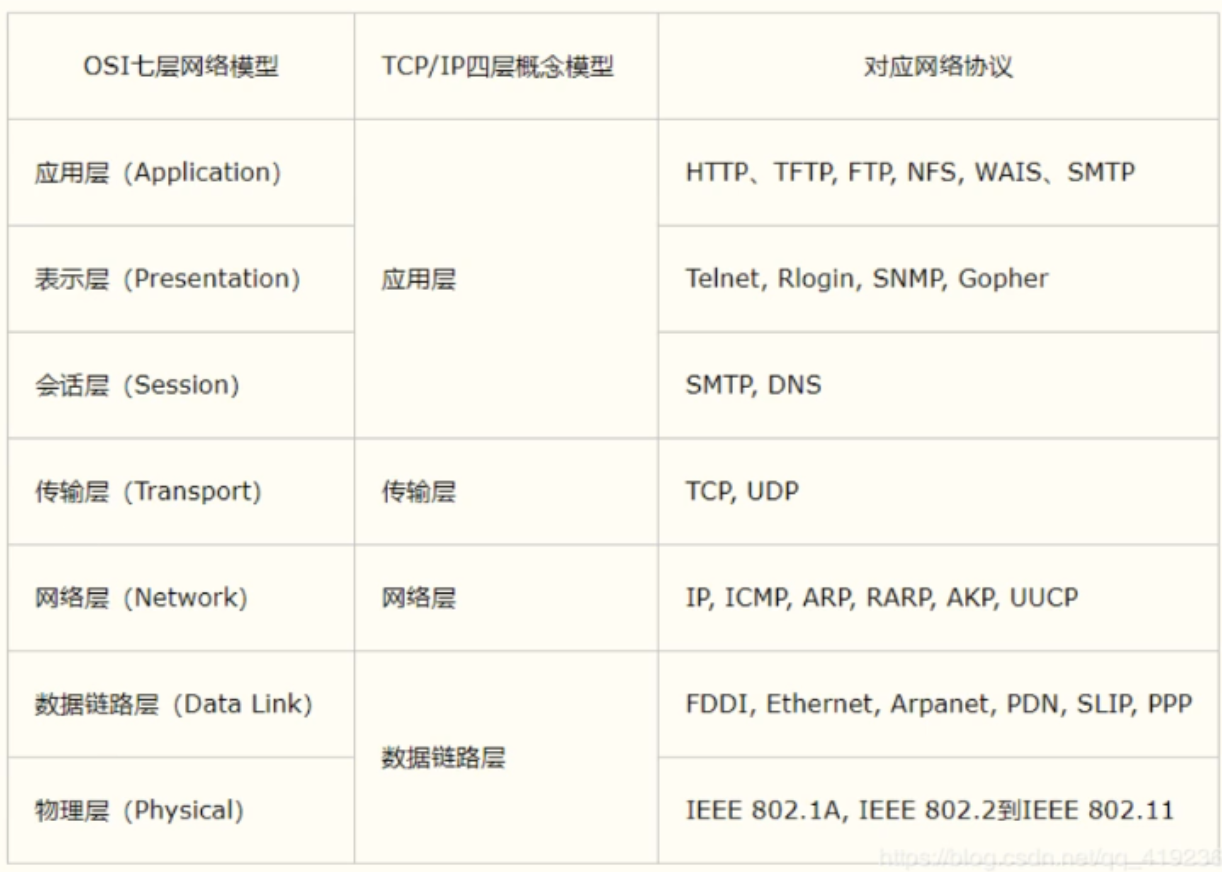
# 网络七层
- 七层划分
- 应用层
- 表示层
- 会话层
- 传输层
- 网络层
- 数据链路层
- 物理层
- 五层划分
- 应用层(包括表示会话)
- 传输层
- 网络层
- 数据链路层
- 物理层
- 每一层都在网络传输中实现了不同的功能作用
- 每一层都将数据进行了一次封装或切割,到指定目标后再反向解除封装、拼接。达到传输目的。
- 应用层(Application Layer)是计算机用户,以及各种应用程序和网络之间的接口,其功能是直接向用户提供服务,完成用户希望在网络上完成的各种工作。
- 应用层为用户提供的服务和协议有:文件服务、目录服务、文件传输服务(FTP)、远程登录服务(Telnet)、电子邮件服务(E-mail)、打印服务、安全服务、网络管理服务、数据库服务等。
- 应用层的主要功能如下:
- 用户接口:应用层是用户与网络,以及应用程序与网络间的直接接口,使得用户能够与网络进行交互式联系。
- 实现各种服务:该层具有的各种应用程序可以完成和实现用户请求的各种服务。
- 其主要功能是“处理用户信息的表示问题,如编码、数据格式转换和加密解密”等。
- 表示层的具体功能如下:
- 数据格式处理:协商和建立数据交换的格式,解决各应用程序之间在数据格式表示上的差异。
- 数据的编码:处理字符集和数字的转换。例如由于用户程序中的数据类型(整型或实型、有符号或无符号等)、用户标识等都可以有不同的表示方式,因此,在设备之间需要具有在不同字符集或格式之间转换的功能。
- 压缩和解压缩:为了减少数据的传输量,这一层还负责数据的压缩与恢复。
- 数据的加密和解密:可以提高网络的安全性。
- 会话层(Session Layer)是用户应用程序和网络之间的接口
- 主要任务是:
- 向两个实体的表示层提供建立和使用连接的方法。将不同实体之间的表示层的连接称为会话。
- 因此会话层的任务就是组织和协调两个会话进程之间的通信,并对数据交换进行管理。
- 传输层(Transport Layer)是通信子网和资源子网的接口和桥梁,起到承上启下的作用。
- 该层的主要任务是:
- 向用户提供可靠的端到端的差错和流量控制,保证报文的正确传输。传输层的作用是向高层屏蔽下层数据通信的细节,即向用户透明地传送报文。
- 该层常见的协议:TCP/IP中的TCP协议、Novell网络中的SPX协议和微软的NetBIOS/NetBEUI协议。
- 传输层提供会话层和网络层之间的传输服务,这种服务从会话层获得数据,并在必要时,对数据进行分割。
- 然后,传输层将数据传递到网络层。
- 因此,传输层负责提供两节点之间数据的可靠传送,当两节点的联系确定之后,传输层则负责监督工作。
- 传输层的主要功能如下:
- 传输连接管理:提供建立、维护和拆除传输连接的功能。
- 处理传输差错:提供可靠的
tcp和不太可靠的udp的数据传输服务、差错控制和流量控制。 - 监控服务质量。
网络层(Network Layer)是OSI参考模型中最复杂的一层,也是通信子网的最高一层。
其主要任务是:
- 通过路由选择算法,为报文或分组通过通信子网选择最适当的路径。
- 数据链路层的数据在这一层被转换为数据包,然后通过路径选择、分段组合、顺序、进/出路由等控制,将信息从一个网络设备传送到另一个网络设备。
- 一般地,数据链路层是解决同一网络内节点之间的通信,而网络层主要解决不同子网间的通信。例如在广域网之间通信时,必然会遇到路由(即两节点间可能有多条路径)选择问题。
在实现网络层功能时,需要解决的主要问题如下:
- 寻址:数据链路层中使用的物理地址(如MAC地址)仅解决网络内部的寻址问题。
- 交换:规定不同的信息交换方式。常见的交换技术有:线路交换技术和存储转发技术,后者又包括报文交换技术和分组交换技术。
- 路由算法:当源节点和目的节点之间存在多条路径时,本层可以根据路由算法,通过网络为数据分组选择最佳路径,并将信息从最合适的路径由发送端传送到接收端。
- 连接服务:与数据链路层流量控制不同的是,前者控制的是网络相邻节点间的流量,后者控制的是从源节点到目的节点间的流量。其目的在于防止阻塞,并进行差错检测。
- 数据链路层(Data Link Layer)负责建立和管理节点间的链路。
- 该层的主要功能是:
- 通过各种控制协议,将有差错的物理信道变为无差错的、能可靠传输数据帧的数据链路。
- 在计算机网络中由于各种干扰的存在,物理链路是不可靠的。因此,这一层的主要功能是在物理层提供的比特流的基础上,通过差错控制、流量控制方法,使有差错的物理线路变为无差错的数据链路,即提供可靠的通过物理介质传输数据的方法。
- 该层通常又被分为介质访问控制(MAC)和逻辑链路控制(LLC)两个子层。
- 数据链路层的具体工作是接收来自物理层的位流形式的数据,并封装成
帧,传送到上一层;同样,也将来自上层的数据帧,拆装为位流形式的数据转发到物理层;并且,还负责处理接收端发回的确认帧的信息,以便提供可靠的数据传输。
MAC子层的主要任务是解决共享型网络中多用户对信道竞争的问题,完成网络介质的访问控制;
LLC子层的主要任务是建立和维护网络连接,执行差错校验、流量控制和链路控制。
- 物理层(Physical Layer)的主要功能是:利用传输介质为数据链路层提供物理连接,实现比特流的透明传输。
- 尽可能屏蔽掉具体传输介质和物理设备的差异。使其上面的数据链路层不必考虑网络的具体传输介质是什么。“透明传送比特流”表示经实际电路传送后的比特流没有发生变化,对传送的比特流来说,这个电路好像是看不见的。
# http2.0/3.0特性
- http1.1是1999年发布,http2.0是2014年11月实现标准化
- 主要解决http1.1问题:
- 反复连接:http1.1有长连接特性,不过返回数据分组标识还是以请求来分的,一个请求一个响应。
- 单向请求:客户端 -> 服务器
- 文件未压缩,会比较大
- HTTP2.0中所有加强性能的核心是二进制传输,在HTTP1.x中,我们是通过文本的方式传输数据
- 在应用层(HTTP)和传输层(TCP)之间增加一个
二进制分帧层 - 在二进制分帧层上,HTTP2.0会将所有传输的信息分为更小的消息和帧,并采用二进制格式编码,其中HTTP1.x的首部信息会被封装到Headers帧,而Request Body则封装到Data帧。
- http传输header多了一个压缩处理,有两个优化点:
- 一个是采用了一个压缩算法,给传输头部进行编码压缩
- 另一个是服务器端和浏览器端各维护一个
索引表,如果要传输已经传过的header就直接传索引就行了,比如说cookie。登录以后,两端各维护一份,然后就可以直接通过键键名来沟通对应的header了。
- 长连接问题产生与优化:
- http1.0是以请求为单位的,一个请求一个返回,TCP连接没有长连接的特性
- http1.1有长连接特性,不过返回数据分组标识还是以请求来分的,一个请求一个响应。
- http2.0传输是以
帧为单位的传输,以数据流为单位区分的,每个帧有一个标识,说明他是哪个数据流的,然后就可以在http连接里直接传输,到了本地的时候再进行一个数据流重组,让帧根据标识重组成数据流,就完成了这个多路复用,一个请求可以返回很多数据流
- 请求优先级:
- 因为一个请求可以返回很多数据流了,所以就可以在服务器端进行优先级的排序,先发送哪些数据流给浏览器。
- 到的顺序不一定能保证按序,因为是多路复用,二进制分帧,到客户端再重组。
- 服务器推送
- websocket
- 浏览器发送一条请求,服务器可以推送多个响应。
- 安全限制:HTTP/2 必须采用 SSL 安全连接
- QUIC (Quick UDP Internet Connections), 快速 UDP 互联网连接。
- QUIC是基于UDP协议的。
- 由于是基于UDP协议,丢包阻塞的问题就不会发生。【HTTP2.0是基于TCP,还是会有TCP队头阻塞(HOL)问题】
TCP协议在收到数据包之后,这部分数据可能是乱序到达的,但是TCP必须将所有数据收集排序整合后给上层使用,如果其中某个包丢失了,就必须等待重传,从而出现某个丢包数据阻塞整个连接的数据使用。
- QUIC在非首次连接的情况下,第一个数据包就可以发业务数据(包含了连接数据),从而在连接延时有很大优势,可以节约数百毫秒的时间。
首次连接传递保存了config包,客户端直接进行保存
有时效性,后续再连接时可以直接使用
# DNS解析
目的就是查找域名对应的IP地址
- 浏览器缓存
- 操作系统缓存(hosts文件)
域名劫持:黑客通过修改hosts文件让域名解析到指定的地址上
- DNS路由缓存:每个路由器内会有缓存,如果访问过的域名路由器会存储缓存。清除方式:重启路由器
- 本地域名服务器
LDNS。一般是比较近的运营商 - 如果都没找到最后去根域名服务器开始
解析。
例:查找【mail.qq.com】
- 本地域名服务器
LDNS向根域名服务器发送请求 - 根域名服务器
root Server:全球13个。可以拿到顶级域名服务器gTLD Server【存储.com的服务器】地址返回给LDNS【.com】 - 顶级域名服务器:拿到域名注册IP地址
Name Server返回给LDNS【qq.com】 - 子域名服务器:如果有二级、三级域名,就会继续向下返回对应的ip给LDNS【mail.qq.com】
自此,解析完毕,LDNS拿到了mail.qq.com的服务器ip地址,返回给客户端,客户端就能和服务器建立连接,进行数据通信了
- 其实DNS客户端和本地DNS服务器是递归,而本地名称服务器和其他名称服务器之间是迭代查询
DNS客户端向本地DNS服务器发送DNS解析请求,之后就处于等待状态,等结果回来,这就是
递归查询
本地DNS服务器发现自己没有域名对应的解析,就会向:
[ 根域名服务器, 顶级域名服务器, 二级域名服务器, 权威域名服务器... ]
进行迭代查询
- 可以进行网络设置让DNS客户端自己进行迭代查询
# CDN资源原理
- 现象概括:cdn资源请求会找距离最近的cdn服务器进行获取,所以会快。
- 购买上传cdn资源,到
cdn总服务器 - 本地请求资源,
DNS解析流程-> 找一遍,找到最近的cdn资源服务器 - 最近的cdn服务器看他那里没有指定资源,就往上级服务器找,最后找到cdn总服务器,拿到资源
- 各级cdn服务器返回的过程也留存了一份
- 以后临近的同样的资源请求就可以在最近的cdn服务器上拿到资源了。
- 购买上传cdn资源,到
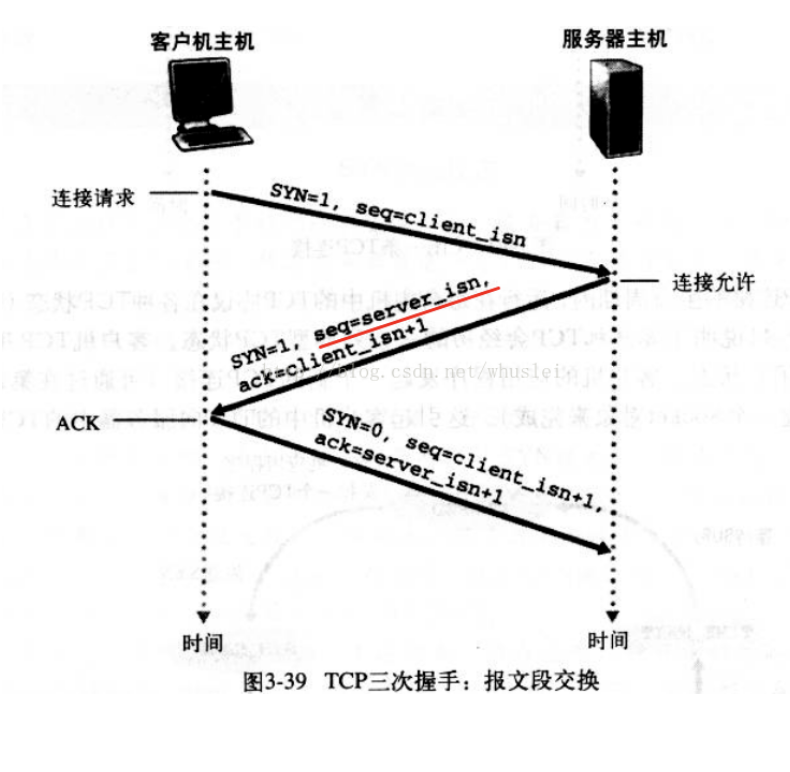
# 三次握手/四次挥手
TCP连接时使用- 三次握手的本质:
- 客户端发送带特殊标记的请求
- 服务端返回此标记,同时附带服务器的标记
- 客户端返回服务器带有同样标记的数据
- 三次握手的目的:
- 1、2客户端确认了服务器的收发数据的能力
- 2、3服务器端确认了客户端的数据收发能力
- 之后再开始数据传输,保证了数据传输的
可靠性
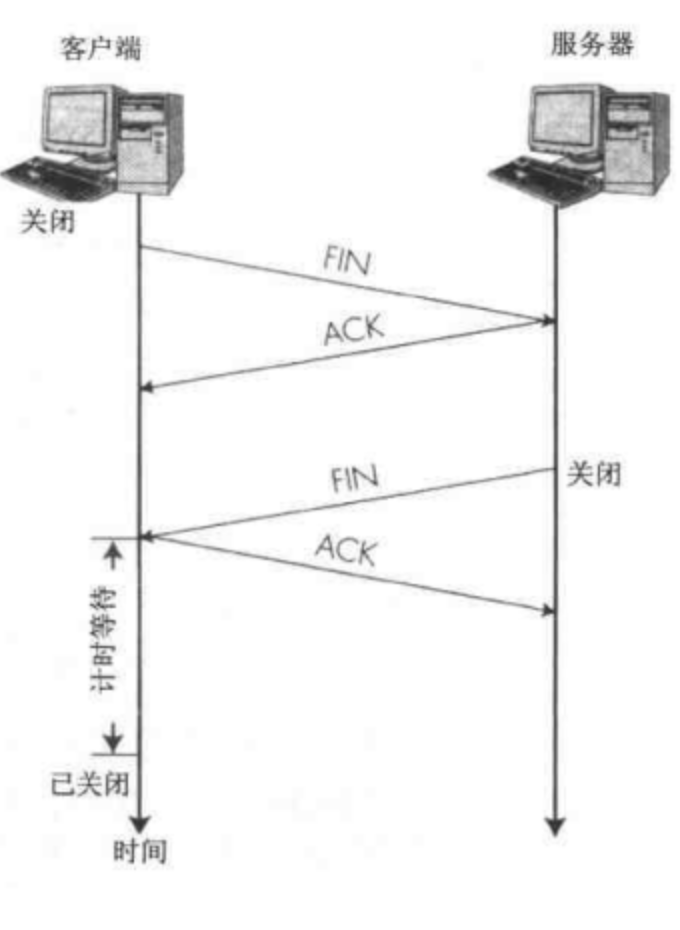
- 四次挥手的本质:
- 客户端发送断开连接请求
- 服务器端响应请求,但不做操作
- 服务器端发送断开请求
- 客户端回应同意断开,结束
- 四次挥手的目的:
- 客户端发送断开请求,服务器可能还在发送数据,因此不能立即断开,但要响应一下,告诉客户端请求收到了
- 服务器数据发送完了,再向客户端发送一个断开请求,但也不能立即断开,防止客户端没收到,还在傻傻的等数据,所以等客户端回应一个消息后,双方默认断开
# HTTPS加密原理
- 对称加密:双方拿着同一个钥匙,既用来加密,也用来解密。
- 钥匙都不能公开
- 如:数字数据加密【-1 * data】,解密【-1 * data】
- 非对称加密:自己有一个公钥,有一个私钥,公钥给别人加密,自己拿私钥才能解开
- 公钥可以公开,私钥不能公开
- 私钥加密可以用公钥解开,公钥加密可以用私钥解开
服务器和客户端怎样建立安全连接?
- 对称加密,那怎么把对称密钥传给对方,且不被黑客知道?
- 非对称加密:
- 客户端给公钥,服务器返回自己的公钥
- 双方开始用公钥加密传递消息
- 万一公钥被黑客掉包成了黑客的公钥了呢? 客户端就一直用黑客的公钥加密消息
- 非对称加密+对称加密
- 客户端发送请求,服务器返回公钥
- 客户端生成随机密钥,用公钥加密返回给服务器,这样随机密钥作为对称加密的钥匙,就能安全的使用对称加密了
- 假如服务器返回公钥的消息被黑客劫持了,返回了黑客的公钥呢?那么随机密钥也只有黑客能解开
最后问题:非对称加密+对称加密的方式,如何证明返回的公钥是服务器的公钥?
- 网站在使用HTTPS前,需要向
CA机构申领一份数字证书,数字证书里含有证书持有者信息、公钥信息等。服务器把证书传输给浏览器,浏览器从证书里获取公钥就行了。 - 签名:防止证书被篡改,把证书原本的内容生成一份“数字签名”
- CA机构拥有非对称加密的私钥和公钥。
- CA机构对证书明文T数据进行hash。
- 对hash后的值用私钥加密,得到数字签名S。
- 明文和数字签名共同生成了数字证书。
- 验证:浏览器有CA机构的公钥
- 拿到证书,得到明文T,签名S。
- 用CA机构的公钥对S解密(由于是浏览器信任的机构,所以浏览器保有它的公钥。),得到S’。
- 用证书里指明的hash算法对明文T进行hash得到T’。
- 显然通过以上步骤,T’应当等于S‘,除非明文或签名被篡改。所以此时比较S’是否等于T’,等于则表明证书可信。
这种方式除非CA机构的私钥泄露,否则黑客很难攻击。因为是用CA机构的私钥进行加密的数字签名,数字签名解开又必须等于明文。 更改明文 -> 解开的签名不会相等 更改签名 -> 浏览器是用CA机构的公钥解密的,也无法生成对应的明文 都更改 -> 浏览器只有CA机构的公钥,除非黑客把浏览器的CA机构公钥改成自己的。浏览器也有对应的保密技术。
- 浏览器会有主流CA证书机构的公钥。
- 服务器向CA机构递交证书申请,含有证书持有者信息、服务器的公钥信息。
- CA机构生成
明文证书并用自己的私钥进行加密生成数字签名,作为完整的证书给服务器。 - 浏览器向服务器发送请求
- 服务器返回自己的证书,含明文部分和签名部分
- 浏览器用CA机构的公钥解开签名部分,看是否完全相等于明文部分
- 完全相等,浏览器信任这份证书,也就信任内部的服务器公钥
- 浏览器生成
随机密钥,用服务器公钥加密返回给服务器 - 服务器用自己的私钥解开随机密钥,作为
对称密钥和浏览器进行交流
# 状态码
1xx(临时响应)表示临时响应并需要请求者继续执行操作的状态代码。
- 100 (继续) 请求者应当继续提出请求。 服务器返回此代码表示已收到请求的第一部分,正在等待其余部分。
- 101 (切换协议) 请求者已要求服务器切换协议,服务器已确认并准备切换。
2xx (成功)表示成功处理了请求的状态代码。
- 200 (成功) 服务器已成功处理了请求。 通常,这表示服务器提供了请求的网页。
- 201 (已创建) 请求成功并且服务器创建了新的资源。
- 202 (已接受) 服务器已接受请求,但尚未处理。
- 203 (非授权信息) 服务器已成功处理了请求,但返回的信息可能来自另一来源。
- 204 (无内容) 服务器成功处理了请求,但没有返回任何内容。
- 205 (重置内容) 服务器成功处理了请求,但没有返回任何内容。
- 206 (部分内容) 服务器成功处理了部分 GET 请求。
3xx (重定向)表示要完成请求,需要进一步操作。 通常,这些状态代码用来重定向。
- 300 (多种选择) 针对请求,服务器可执行多种操作。 服务器可根据请求者 (user agent) 选择一项操作,或提供操作列表供请求者选择。
- 301 (永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。
- 302 (临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
- 303 (查看其他位置) 请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。
- 304 (未修改) 自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容。
- 305 (使用代理) 请求者只能使用代理访问请求的网页。 如果服务器返回此响应,还表示请求者应使用代理。
- 307 (临时重定向) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
4xx(请求错误)这些状态代码表示请求可能出错,妨碍了服务器的处理。
- 400 (错误请求) 服务器不理解请求的语法。
- 401 (未授权) 请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。
- 403 (禁止) 服务器拒绝请求。
- 404 (未找到) 服务器找不到请求的网页。
- 405 (方法禁用) 禁用请求中指定的方法。
- 406 (不接受) 无法使用请求的内容特性响应请求的网页。
- 407 (需要代理授权) 此状态代码与 401(未授权)类似,但指定请求者应当授权使用代理。
- 408 (请求超时) 服务器等候请求时发生超时。
- 409 (冲突) 服务器在完成请求时发生冲突。 服务器必须在响应中包含有关冲突的信息。
- 410 (已删除) 如果请求的资源已永久删除,服务器就会返回此响应。
- 411 (需要有效长度) 服务器不接受不含有效内容长度标头字段的请求。
- 412 (未满足前提条件) 服务器未满足请求者在请求中设置的其中一个前提条件。
- 413 (请求实体过大) 服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。
- 414 (请求的 URI 过长) 请求的 URI(通常为网址)过长,服务器无法处理。
- 415 (不支持的媒体类型) 请求的格式不受请求页面的支持。
- 416 (请求范围不符合要求) 如果页面无法提供请求的范围,则服务器会返回此状态代码。
- 417 (未满足期望值) 服务器未满足”期望”请求标头字段的要求。
428 Precondition Required (要求先决条件) 先决条件是客户端发送 HTTP 请求时,如果想要请求能成功必须满足一些预设的条件。
一个好的例子就是 If-None-Match 头,经常在 GET 请求中使用,如果指定了 If-None-Match ,那么客户端只在响应中的 ETag 改变后才会重新接收回应。
先决条件的另外一个例子就是 If-Match 头,这个一般用在 PUT 请求上用于指示只更新没被改变的资源,这在多个客户端使用 HTTP 服务时用来防止彼此间不会覆盖相同内容。
当服务器端使用 428 Precondition Required 状态码时,表示客户端必须发送上述的请求头才能执行请求,这个方法为服务器提供一种有效的方法来阻止 'lost update' 问题。
429 Too Many Requests (太多请求)当你需要限制客户端请求某个服务数量时,该状态码就很有用,也就是请求速度限制。 431 Request Header Fields Too Large (请求头字段太大)某些情况下,客户端发送 HTTP 请求头会变得很大,那么服务器可发送 431 Request Header Fields Too Large 来指明该问题。
5xx(服务器错误)这些状态代码表示服务器在尝试处理请求时发生内部错误。 这些错误可能是服务器本身的错误,而不是请求出错。
500 (服务器内部错误) 服务器遇到错误,无法完成请求。
501 (尚未实施) 服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码。
502 (错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。
503 (服务不可用) 服务器目前无法使用(由于超载或停机维护)。 通常,这只是暂时状态。
504 (网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。
505 (HTTP 版本不受支持) 服务器不支持请求中所用的 HTTP 协议版本。
511 Network Authentication Required (要求网络认证) 对我来说这个状态码很有趣,如果你在开发一个 HTTP 服务器,你不一定需要处理该状态码,但如果你在编写 HTTP 客户端,那这个状态码就非常重要。
# TCP
- TCP连接复用技术通过将前端多个客户的HTTP请求复用到后端与服务器建立的一个TCP连接上。这种技术能够大大减小服务器的性能负载,减少与服务器之间新建TCP连接所带来的延时,并最大限度的降低客户端对后端服务器的并发连接数请求,减少服务器的资源占用。
- 三次握手确认服务器和浏览器的数据收发能力
- 断点续传,服务器发送给客户端数据以后,客户端有一个回传消息,代表收到哪一个字段了,假如网络波动某一个数据段丢包了,服务器会从丢包的地方从新传输。
# 网络攻防
# XSS攻击
- XSS攻击通常指的是通过利用网页开发时留下的漏洞,通过巧妙的方法注入恶意指令代码到网页,使用户加载并执行攻击者恶意制造的网页程序。
- 常见情况:
- 展示用户评论,用户留下恶意脚本
- 利用ajax执行一些用户自身才能执行的操作
- 防范:
- 非必要永远不要用
v-html/innerHTML - 如果要展示用户输入,用
v-text/innerText - 如果一定要解析,先转义
reg = /<[^>]*>(.*?)<\/[^>]*>/gi - 或直接
</>转义成</>
- 非必要永远不要用
- 一个简单的评论系统
server.js
const path = require('path');
const fs = require('fs');
const express = require('express');
const app = express();
const bdParser = require('body-parser');
app.use(bdParser.json());
app.use(bdParser.urlencoded({extended: false}));
app.listen('8888');
let database = {};
function getDatabase() {
const uri = path.join(__dirname, 'database.json');
const json = fs.readFileSync(uri).toString();
database = JSON.parse(json);
}
function writeDatabase({ name, comment }) {
database[name] = comment;
const uri = path.join(__dirname, 'database.json');
fs.writeFile(
uri,
JSON.stringify(database),
() => console.log('写入数据库成功')
);
}
getDatabase();
app.get('/', (req, res) => {
const url = path.join(__dirname, './index.html')
const file = fs.readFileSync(url).toString();
res.send(file);
});
app.post('/comment', (req, res) => {
const { name, comment } = req.body;
writeDatabase({name, comment});
res.json({ seccess: true });
})
app.get('/api/comments', (req, res) => {
res.json(database);
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
database.json
{"张三":"我真帅","赵四":"你放屁","王五":"网络空间,不要吹牛"}
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
</head>
<body>
<table class="comments">
</table>
<div>
<input type="text" class="name" placeholder="姓名">
<input type="text" id="comment" placeholder="评论">
<button id="commit">提交</button>
</div>
<script>
function initComment() {
fetch('/api/comments')
.then(res => res.json())
.then(comments => {
const commentsBox = document.querySelector('.comments');
commentsBox.innerHTML = '';
Object.entries(comments).forEach(([key, val]) => {
const tr = document.createElement('tr');
const td1 = document.createElement('td');
const td2 = document.createElement('td');
commentsBox.appendChild(tr);
tr.appendChild(td1);
tr.appendChild(td2);
td1.innerHTML = key + ':';
td2.innerHTML = val;
})
}
)
}
initComment();
const commitBtn = document.querySelector('#commit');
commitBtn.addEventListener('click', () => {
const nameBox = document.querySelector('.name');
const valBox = document.querySelector('#comment');
const name = nameBox.value;
const val = valBox.value;
if (val.trim().length > 0) {
fetch('/comment', {
body: JSON.stringify({name, comment: val}),
headers: { 'Content-Type': 'application/json' },
method: 'post'
}).then(res => res.json())
.then(res => {
nameBox.value = '';
valBox.value = '';
initComment();
});
}
})
</script>
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
- 用户本人正常操作
- 恶意植入操作
server.js
const path = require('path');
const fs = require('fs');
const express = require('express');
const app = express();
const bdParser = require('body-parser');
app.use(bdParser.json());
app.use(bdParser.urlencoded({extended: false}));
app.listen('8888');
let database = {};
function getDatabase() {
const uri = path.join(__dirname, 'database.json');
const json = fs.readFileSync(uri).toString();
database = JSON.parse(json);
}
function writeDatabase({ name, comment }) {
database[name] = comment;
const uri = path.join(__dirname, 'database.json');
fs.writeFile(
uri,
JSON.stringify(database),
() => console.log('写入数据库成功')
);
}
getDatabase();
app.get('/', (req, res) => {
const url = path.join(__dirname, './index.html')
const file = fs.readFileSync(url).toString();
res.send(file);
});
app.post('/comment', (req, res) => {
const { name, comment } = req.body;
writeDatabase({name, comment});
res.json({ seccess: true });
})
app.get('/api/comments', (req, res) => {
res.json(database);
})
app.get('/api/clear', (req, res) => {
database = {};
const url = path.join(__dirname, './index.html')
const file = fs.readFileSync(url).toString();
res.send(file);
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
database.json
{"张三":"我真帅","赵四":"你放屁","王五":"网络空间,不要吹牛"}
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
</head>
<body>
<table class="comments">
</table>
<div>
<input type="text" class="name" placeholder="姓名">
<input type="text" id="comment" placeholder="评论">
<button id="commit">提交</button>
</div>
<button id="clear">删除所有评论</button>
<script>
function initComment() {
fetch('/api/comments')
.then(res => res.json())
.then(comments => {
const commentsBox = document.querySelector('.comments');
commentsBox.innerHTML = '';
Object.entries(comments).forEach(([key, val]) => {
const tr = document.createElement('tr');
const td1 = document.createElement('td');
const td2 = document.createElement('td');
commentsBox.appendChild(tr);
tr.appendChild(td1);
tr.appendChild(td2);
td1.innerHTML = key + ':';
td2.innerHTML = val;
})
}
)
}
initComment();
const commitBtn = document.querySelector('#commit');
commitBtn.addEventListener('click', () => {
const nameBox = document.querySelector('.name');
const valBox = document.querySelector('#comment');
const name = nameBox.value;
const val = valBox.value;
if (val.trim().length > 0) {
fetch('/comment', {
body: JSON.stringify({name, comment: val}),
headers: { 'Content-Type': 'application/json' },
method: 'post'
}).then(res => res.json())
.then(res => {
nameBox.value = '';
valBox.value = '';
initComment();
});
}
})
const clear = document.querySelector('#clear');
clear.addEventListener('click', () => {
fetch('/api/clear')
.then(res => initComment())
})
</script>
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
# csrf攻击
- 触发方式:
- 在登录一个网站,做完操作后cookie并没有过期
- 登录另一个网站,另一个网站有一个攻击原先网站的操作链接,并且由于浏览器的机制,向原网站发送请求会携带原本的cookies
- 这样你就在另一个网站发送了原网站的恶意请求。
- 防御方式:
- 重要操作时设置短信验证、做一个随机数验证码验证等
- 验证请求头的refer字段,存储的是发起请求的网址,如果不是信任的网址直接拒绝
- token,在请求的url中拼接一个本段会话有效的token,重要请求设置拦截器,如果没有token或者token不对就拒绝。
- 模拟网抑云的后端,客户本人拥有三个能力:
- 登录
- 登出
- 注销账号
const path = require('path');
const fs = require('fs');
const bdParser = require('body-parser');
const express = require('express');
const app = express();
app.use(bdParser.json());
app.use(bdParser.urlencoded({extended: false}));
const cookieParser = require('cookie-parser');
app.use(cookieParser());
app.listen('8888');
let database = {
hdy: {
pwd: '123',
songs: [
'穷叉叉',
'富叉叉',
'两只老虎'
]
},
'张三': {
pwd: '456',
songs: [
'黑猫警长',
'六只老虎'
]
}
};
app.get('/', (req, res) => {
const url = path.join(__dirname, './index.html')
const file = fs.readFileSync(url).toString();
res.send(file);
});
app.post('/login', (req, res) => {
const { name, pwd } = req.body;
if (database[name] && database[name].pwd === pwd) {
const { songs } = database[name];
res.cookie('name', name);
res.cookie('pwd', pwd);
res.json({ songs });
} else {
res.status(304).json({msg: '用户不存在'});
}
})
app.get('/logout', (req, res) => {
res.clearCookie('name');
res.clearCookie('pwd');
res.json({success: true});
})
// 注销账号
app.get('/byby', (req, res) => {
const { name } = req.cookies;
delete database[name];
res.clearCookie('name');
res.clearCookie('pwd');
res.json({success: true});
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
- 正常操作
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
</head>
<body>
<div id="app">
<div v-if="admin">
<div>你好,{{admin}}</div>
<ul>
<li v-for="song of songs" :key="song">{{song}}</li>
</ul>
<button @click="logout">退出</button>
<button @click="del">注销</button>
</div>
<div v-else>
<div>欢迎来到网抑云,请先登录</div>
<input type="text" v-model="name">
<input type="text" v-model="pwd">
<button @click="login">登录</button>
</div>
<div>{{tip}}</div>
</div>
<script src="https://cdn.jsdelivr.net/npm/vue@2/dist/vue.js"></script>
<script>
const app = new Vue({
el: '#app',
data() {
return {
admin: '',
songs: [],
name: '',
pwd: '',
tip: ''
}
},
mounted() {
this.defaultLogin();
},
methods: {
defaultLogin() {
const cookie = document.cookie;
const reg = /\b(name|pwd)\b=[^;]*/g;
if (reg.test(cookie)) {
const userInfo = Object.fromEntries(cookie.match(reg).map(item => item.split('=')));
Object.entries(userInfo).forEach(([key, val]) => this[key] = decodeURI(val));
this.login();
}
},
login() {
fetch('/login', {
method: 'post',
body: JSON.stringify({ name: this.name, pwd: this.pwd }),
headers: { 'Content-Type': 'application/json' }
})
.then(res => {
if (res.ok) {
return res.json();
} else {
return Promise.reject();
}
})
.then(res => {
this.songs = res.songs;
this.admin = this.name;
this.name = '';
this.pwd = '';
})
.catch(res => {
this.tip = '账号或密码错误';
})
},
logout() {
fetch('/logout')
.then(res => this.admin = '');
},
del() {
fetch('/byby')
.then(res => this.admin = '');
},
}
})
</script>
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
- 网抑云cookie保持在有效期,在黑客网站点击了恶意攻击按钮,浏览器向网抑云服务器发送请求携带了cookie,导致服务器以为是我本人想注销账号,受到很大的损失
<body>
<h1>网抑云周边商城</h1>
<a href="http://localhost:8888/byby">点击就送网抑云会员</a>
</body>
2
3
4
# 浏览器相关
# 浏览器关键渲染路径
- 生成 DOM 会从远程下载 Byte,并根据相应的编码 (如 utf8) 转化为字符串,通过 AST 解析为 Token,生成 Node 及最后的 DOM。
- 当解析 CSS 文件时,最终会生成 CSSOM
- DOM 与 CSSOM 会一起生成 Render Tree,只包含渲染网页所需的节点。
- 计算每一个元素在设备视口内的确切位置和大小
- 将渲染树中的每个节点转换成屏幕上的实际像素,这一步通常称为绘制或栅格化
浏览器元素大小发生变化,使周围元素布局也要发生变化,就要从4
重排开始,性能开销大
如果只是本元素发生变化,不会影响整体的布局,如背景颜色、字体颜色、盒子内容时,就只会触发5重绘,性能开销小
# src和href的区别
- src请求的资源会中断当前页面解析,如图片、script:在浏览器下载,编译,执行这个文件之前页面的加载和处理会被暂停。
- 而link的href是被当做一个样式表进行加载。浏览器识别当前资源是一个样式表,页面解析不会暂停,因此建议使用link标签而不是@import来把样式表导入到html文档里。
# 浏览器缓存
- 服务器说明:在指定时间内这个资源都有效,不要再发请求了
- 强缓存主要包括
expires和cache-control,pragma。expires字段表示资源的过期时间。expires: Thu, 01 Jan 2022 10:20:33 GMT1问题:客户端时间可以修改,快慢不一致
cache-control:主要有 max-age 和 s-maxage、public 和 private、no-cache 和 no-store 等值。在浏览器中,
max-age和s-maxage都起作用,而且 s-maxage 的优先级高于 max-age。在代理服务器中,只有 s-maxage 起作用。
public表示该资源可以被所有客户端和代理服务器缓存,而private表示该资源仅能客户端缓存。默认值是 private,当设置了 s-maxage 的时候表示允许代理服务器缓存,相当于 public。
no-cache表示的是不直接询问浏览器缓存情况,而是去向服务器验证当前资源是否更新(即协商缓存)。no-store完全不使用缓存策略。pragma的值有 no-cache 和 no-store,表示意思同 cache-control
- 优先级:pragma -> cache-control -> expires
- 协商缓存响应头主要包括
last-modified和etaglast-modified:精确度只能到秒
只要编辑了,不管内容是否真的有改变,都会以这最后修改的时间作为判断依据etag: 是响应内容某个指定版本的一个标识符,通常可以用文件的 hash 或者某个固定规则的算法,比如文章最后修改时间的 MD5 等。- ETag 另一个典型的用法是缓存未更改的资源
- etag 会基于资源的内容编码生成一串唯一的标识字符串,只要内容不同,就会生成不同的 etag
etag: "620b0851-17c42"
- 当再次请求该资源时,请求头会带有
if-none-match字段,值是之前返回的 etag 值,如:if-none-match:"620b0851-17c42"。
- 服务端会根据该资源当前的内容生成对应的标识字符串和该字段进行对比,若一致则代表未改变可直接使用本地缓存并返回 304;若不一致则返回新的资源(状态码200)并修改返回的 etag 字段为新的值。
- etag 比 last-modified 更加精准地感知了变化,所以 etag 优先级也更高